Smoking Status Variable - modifying existing rules
In this tutorial, we will be using the smoking status example data and existing rulesets that will allow us to classify charts according to the following labels: Current smoker, Former smoker, Never smoked, or Not dictated.
- Download the smoking status example data.
text_data.csvlabels_train.csvlabels_valid.csv
- Download the existing smoking status rules.
- After downloading the rules, extract the zipped file and save the rules to a folder. Remember the path to this folder! You will need it later in step 5.
- After downloading the rules, extract the zipped file and save the rules to a folder. Remember the path to this folder! You will need it later in step 5.
- Upload the text data file.
- From the Settings view, press on the Project Settings tab.
- Press on the Data File button to add the smoking status text data file (
text_data.csv). - Set the
Data ID columnto be 0. - Set the
Data First Rowto be 1. - Set the
Data Columnto be 1.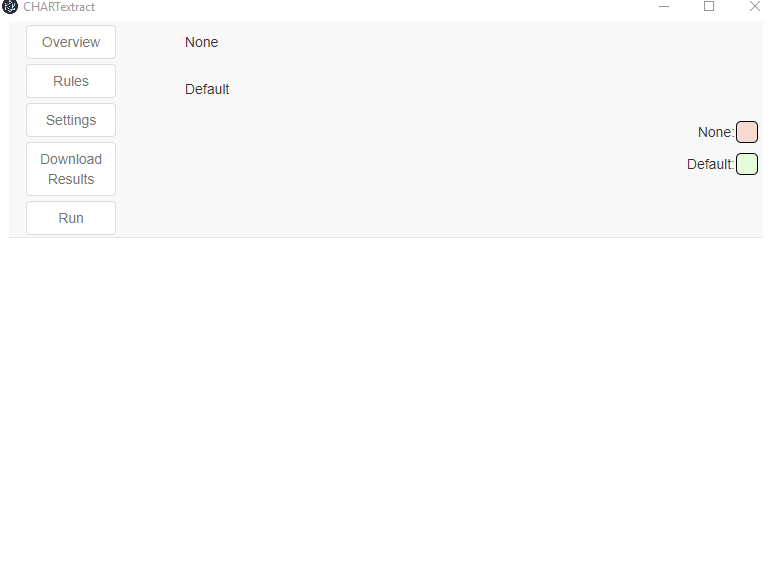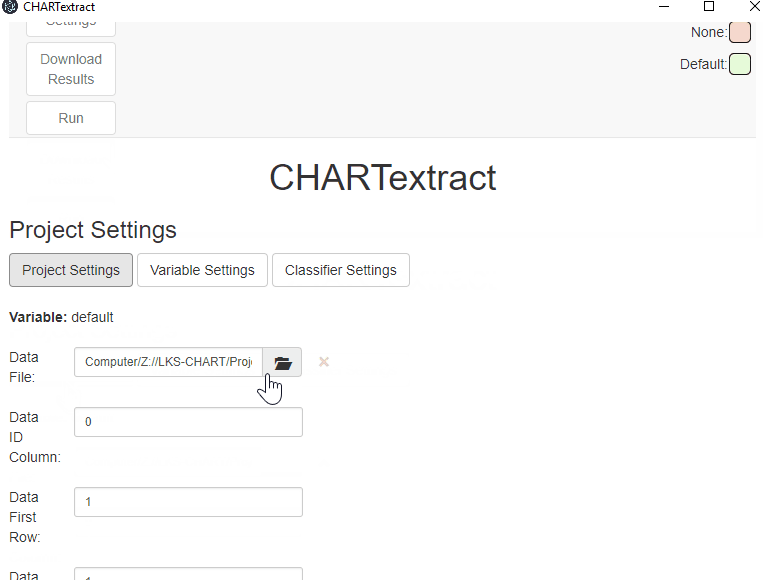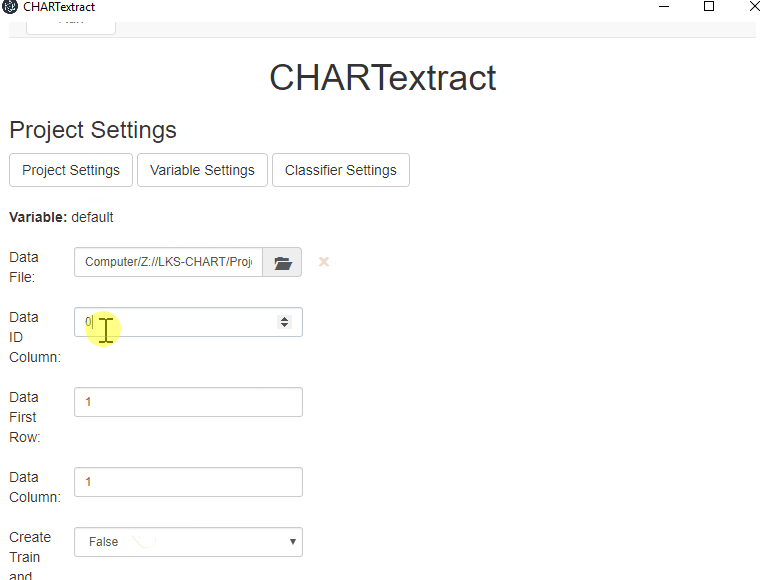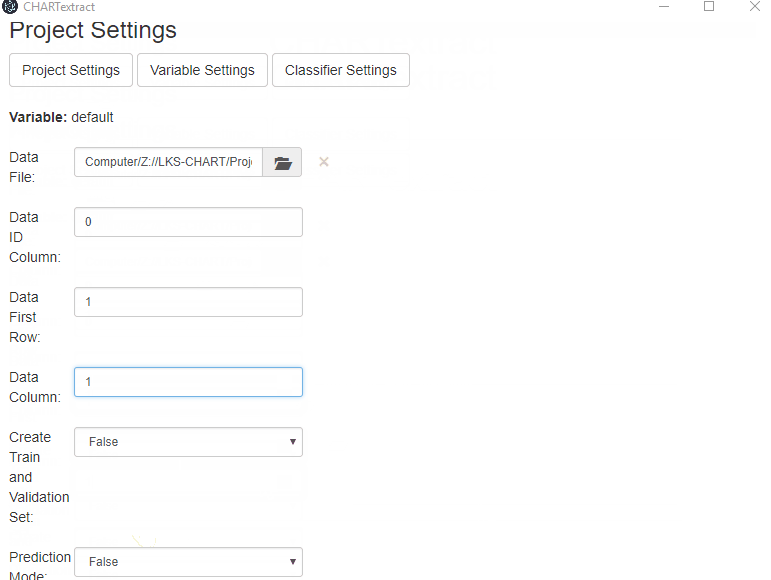
- Upload the labels files.
- Still in the Project Settings tab, set the
Create Train and Validation Setflag to be False. We don’t need to create train and validation sets, since we will be uploading our own train and validation labels. - Set
Prediction Modeto be False. - Press on the folder icon next to
Train Label Fileto upload the smoking status train data labels (labels_train.csv). - Press on the folder icon next to
Valid Label Fileto upload the smoking status valid data labels (labels_valid.csv). - Set the
Label ID Columnto be 0. - Set the
Label First Rowto be 1.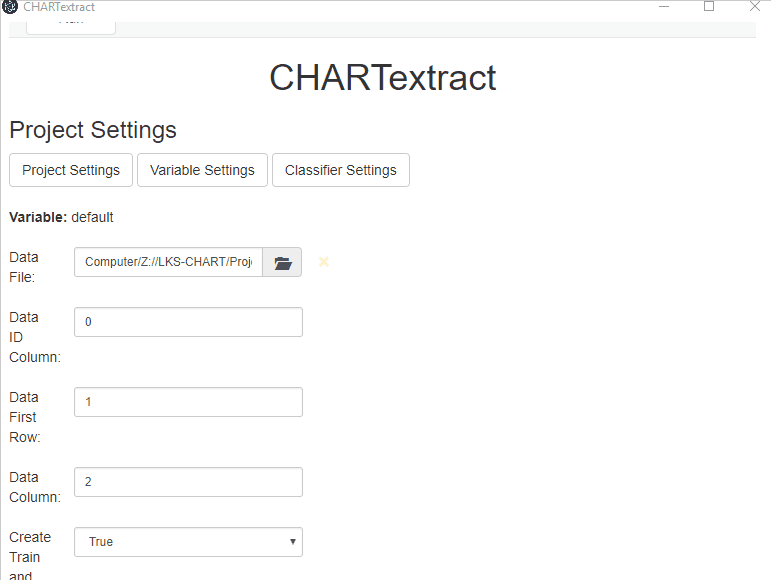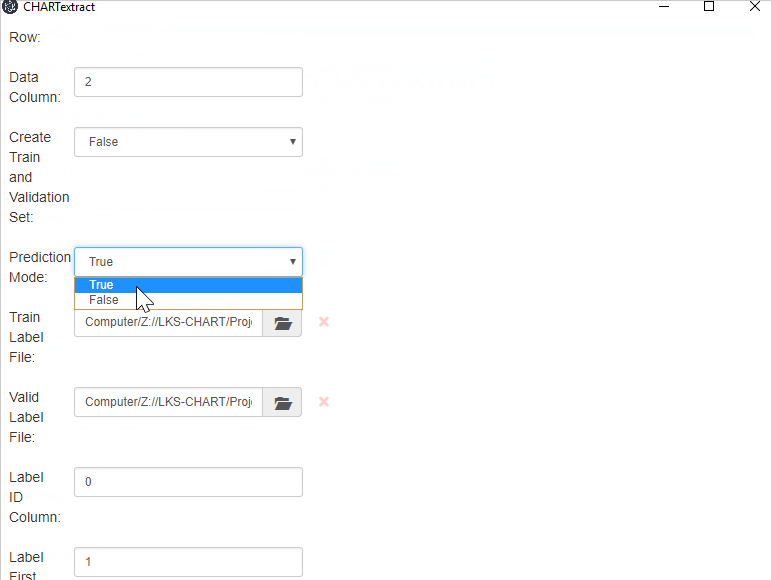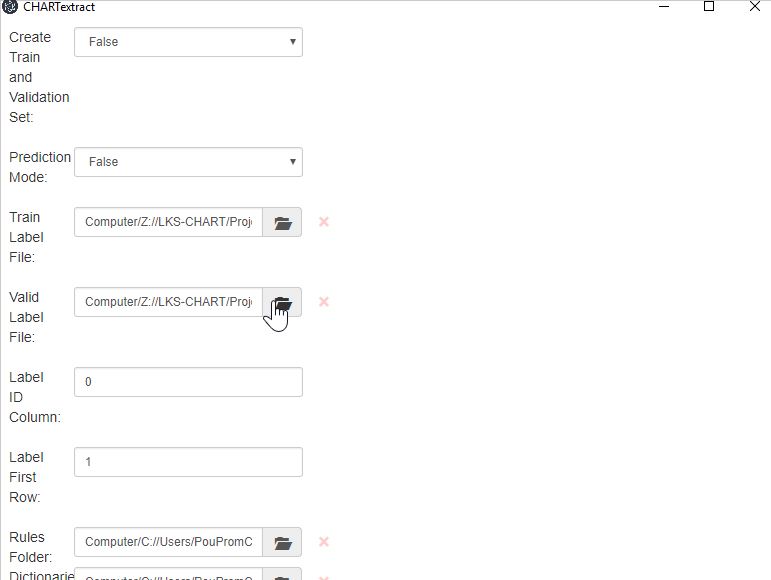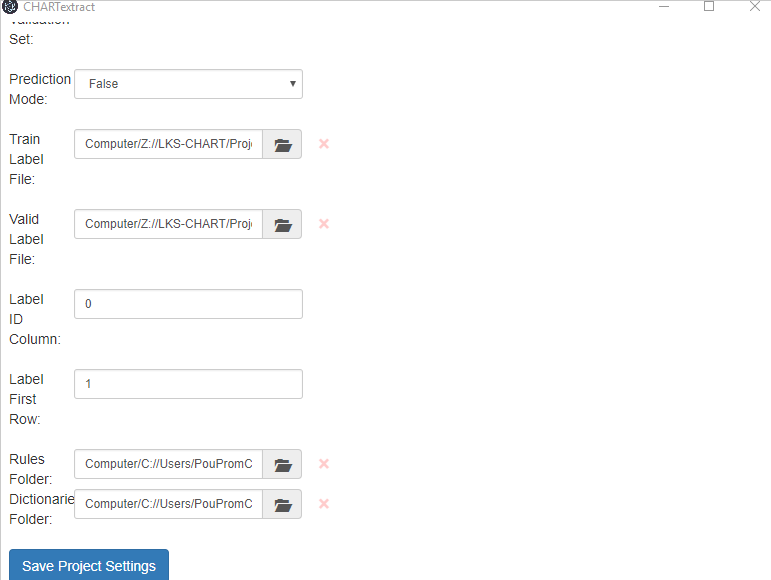
- Still in the Project Settings tab, set the
- Set Rules folder file.
- Still in the Project Settings tab, press on the folder icon next to
Rules Folder. Set the rules folder to be the folder from Step 2 (i.e., the folder where you saved the smoking status rules). - Press on the
Save Project Settingsbutton.
- Still in the Project Settings tab, press on the folder icon next to
- Load the variable rules.
- Go to the Variable Settings tab.
- In the dropdown menu for
Current variable, you should see thesmoking_statusvariable. Select it. - Press on the
Save Variable Settingsbutton.
- Set the classifier settings.
- Press on the Classifier Settings tab.
- Set the
Classifier Typeto RegexClassifier. - Set the
Negative LabeltoNot dictated.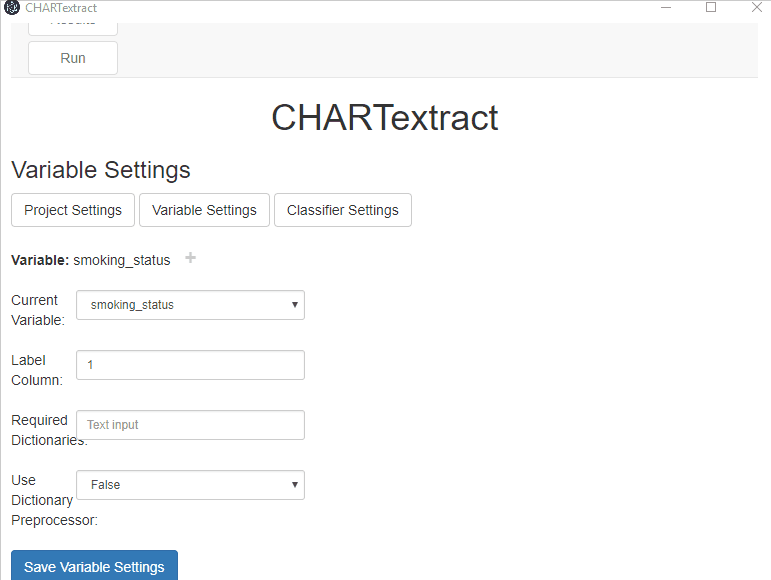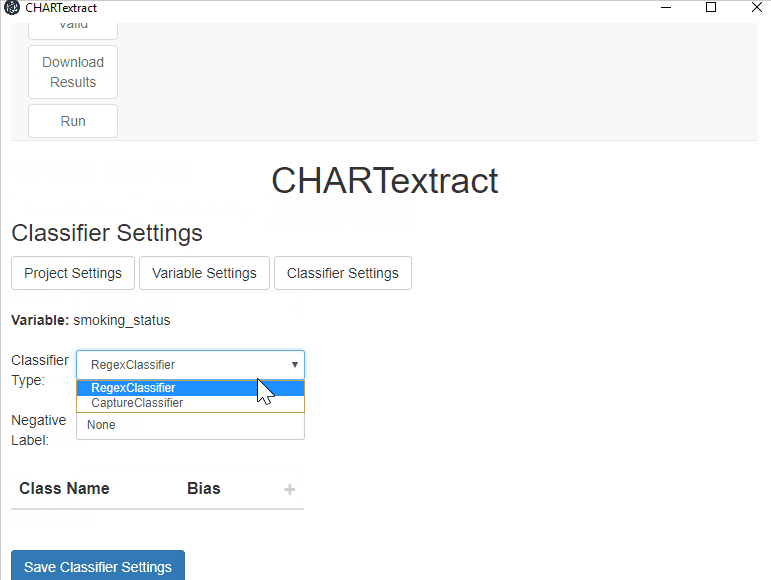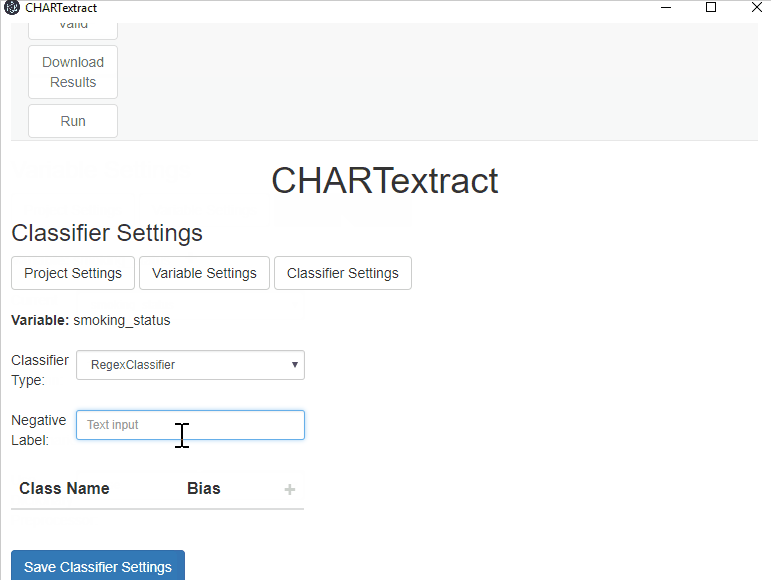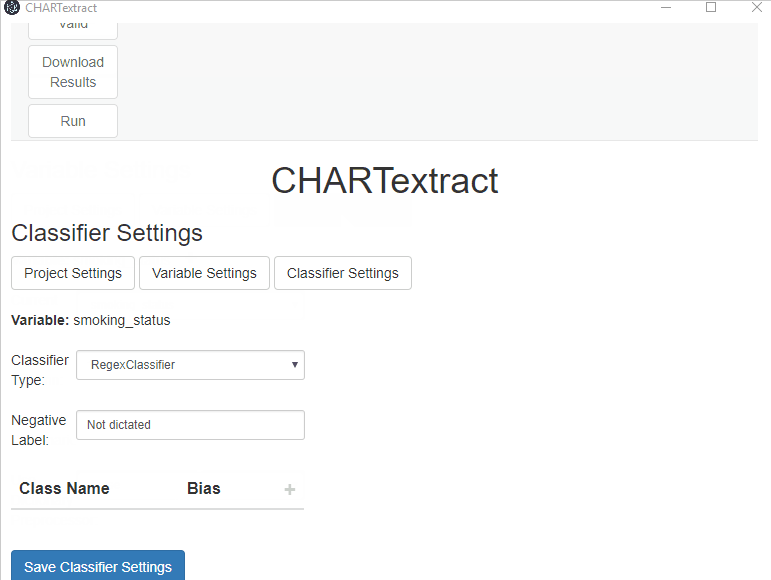
- View the existing rules.
- Go to the Rules view.
- You should see the
Current smoker,Former smokerandNever smokedlabels.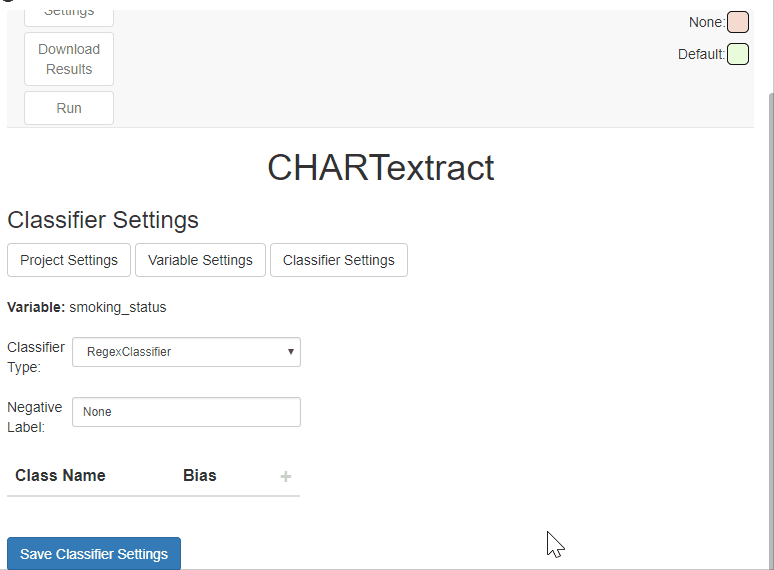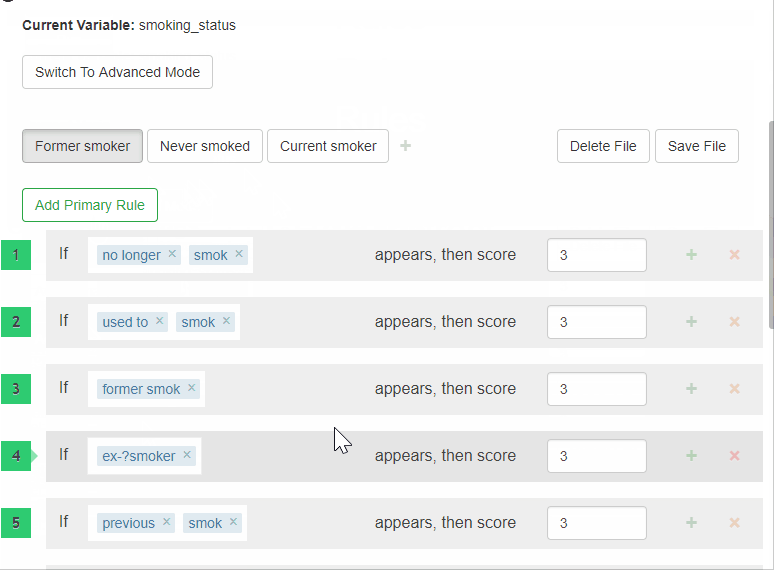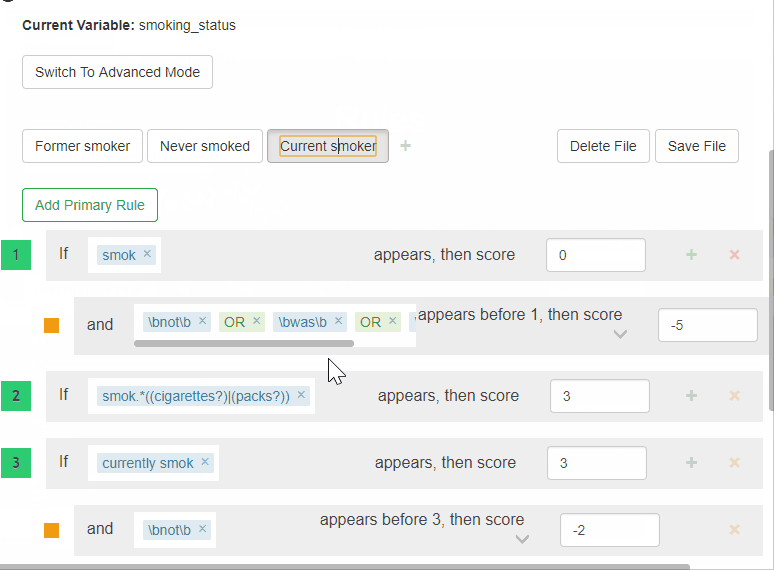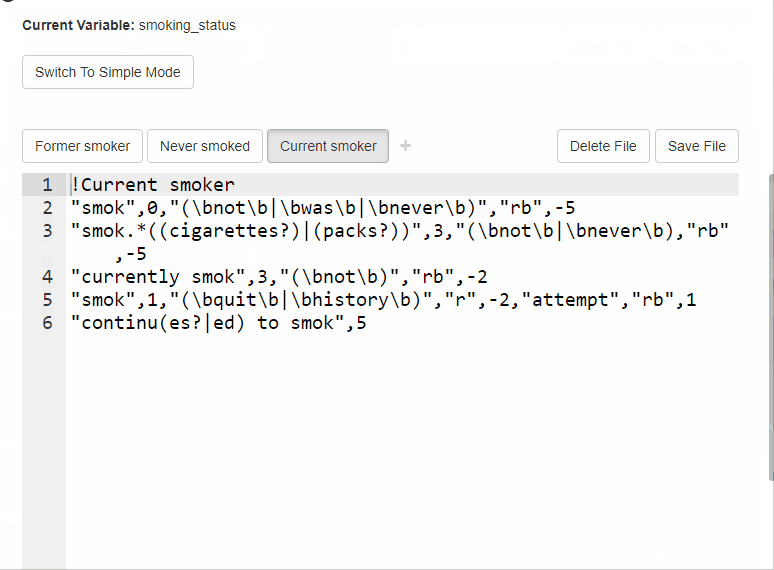
- Run the tool.
- Press on the Run button.
- The top pane will display misclassified charts (i.e., the label predicted by CHARTextract is not the same as the ground truth label).
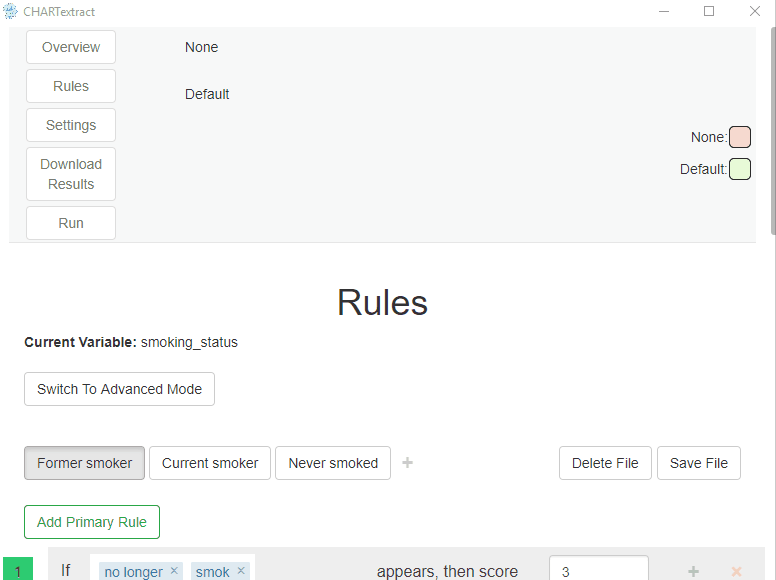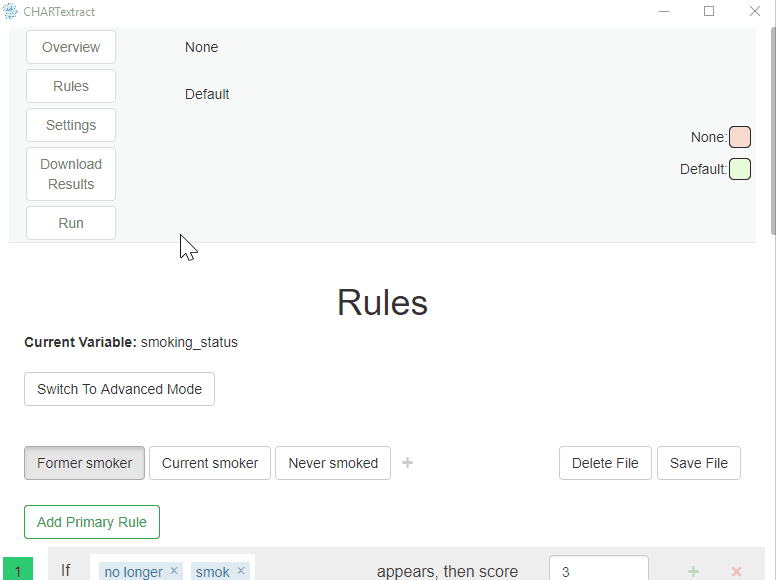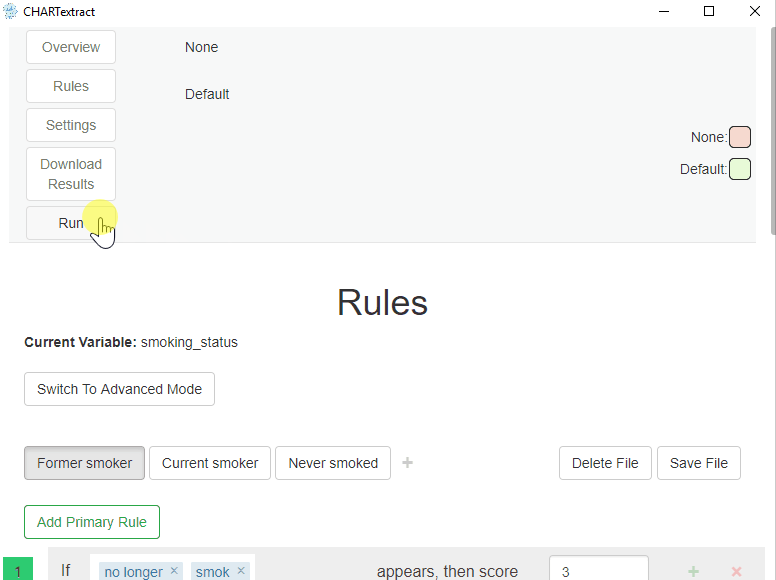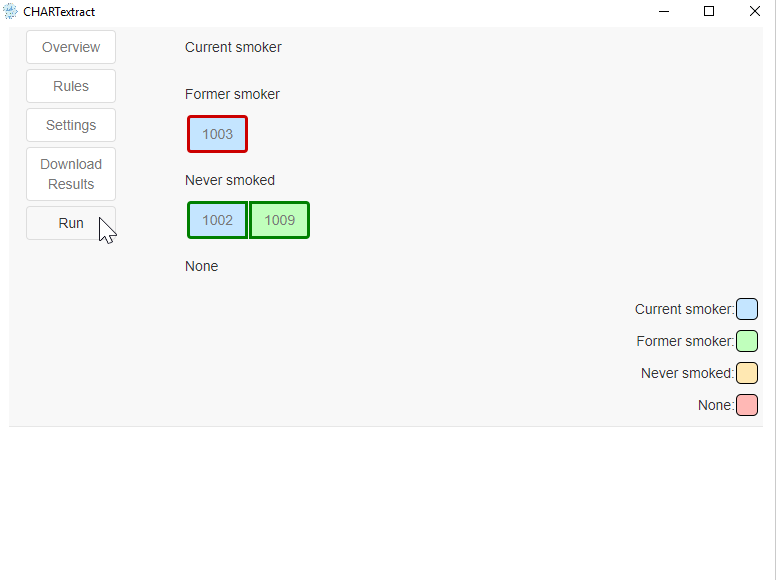
- Refine the rules.
- Keep in mind that the rules we are releasing were developed on data that may be different from yours. Thus, we will want to refine the rules
- Press on the misclassified chart with ID 1003.
- CHARTextract classified this chart as
Current smoker, but its ground truth label isFormer smoker. - If you press on the yellow highlighted text, you will see that CHARTextract detected the words “former smoker of 1 pack”, and this gave a score of 4 to the
Current smokerlabel and a score of 3 to theFormer smokerlabel. - The rules in their current state are not able to correctly classify this chart. Let’s fix this.
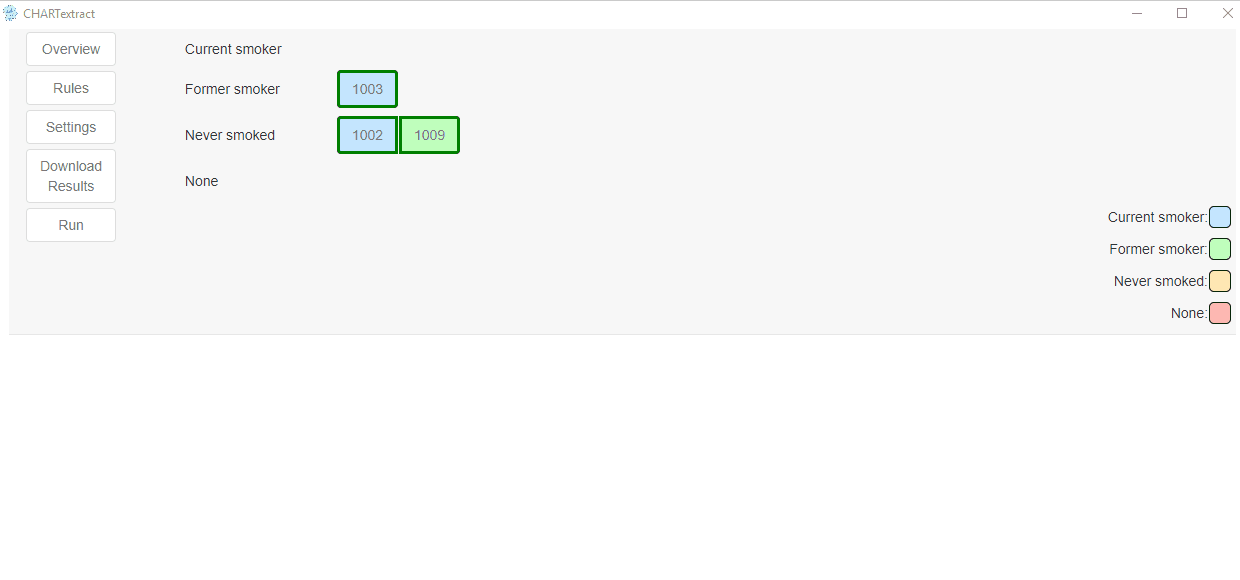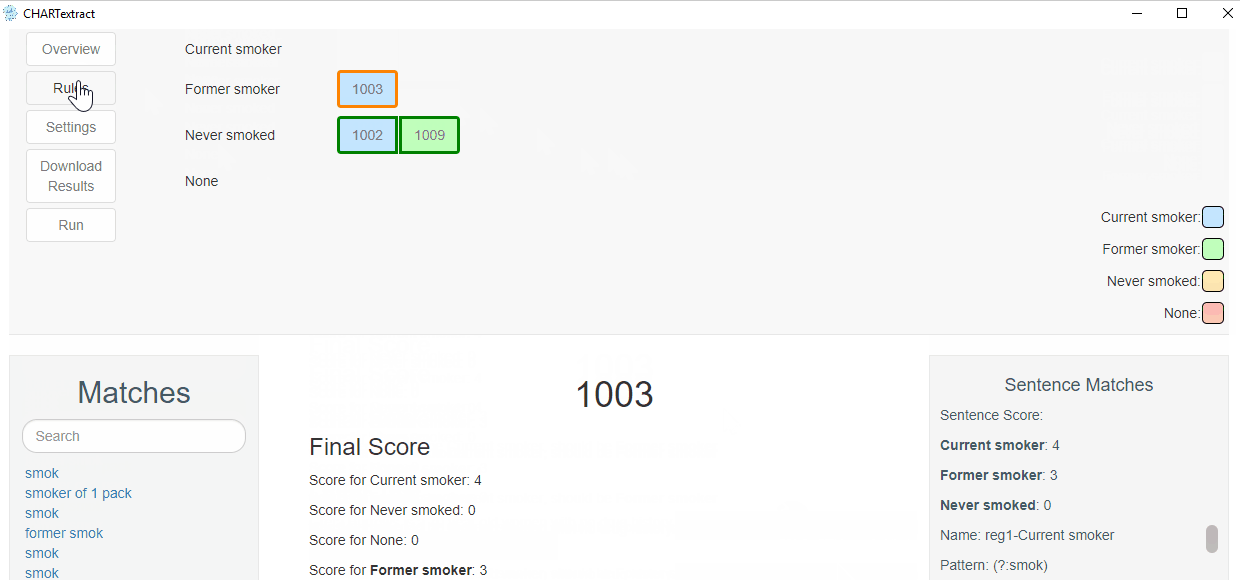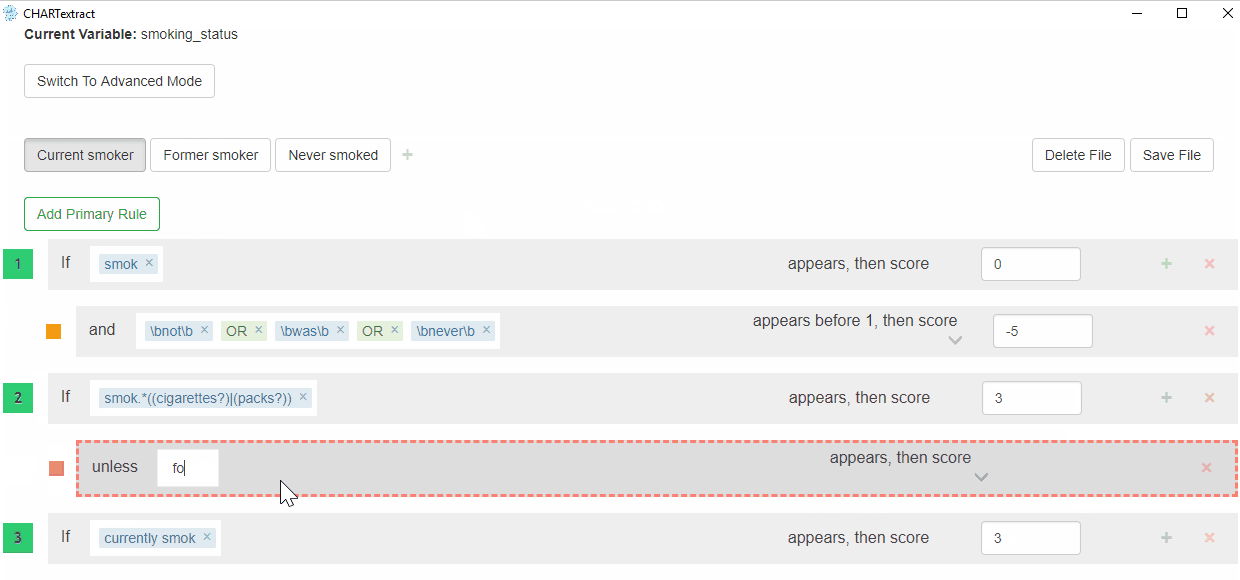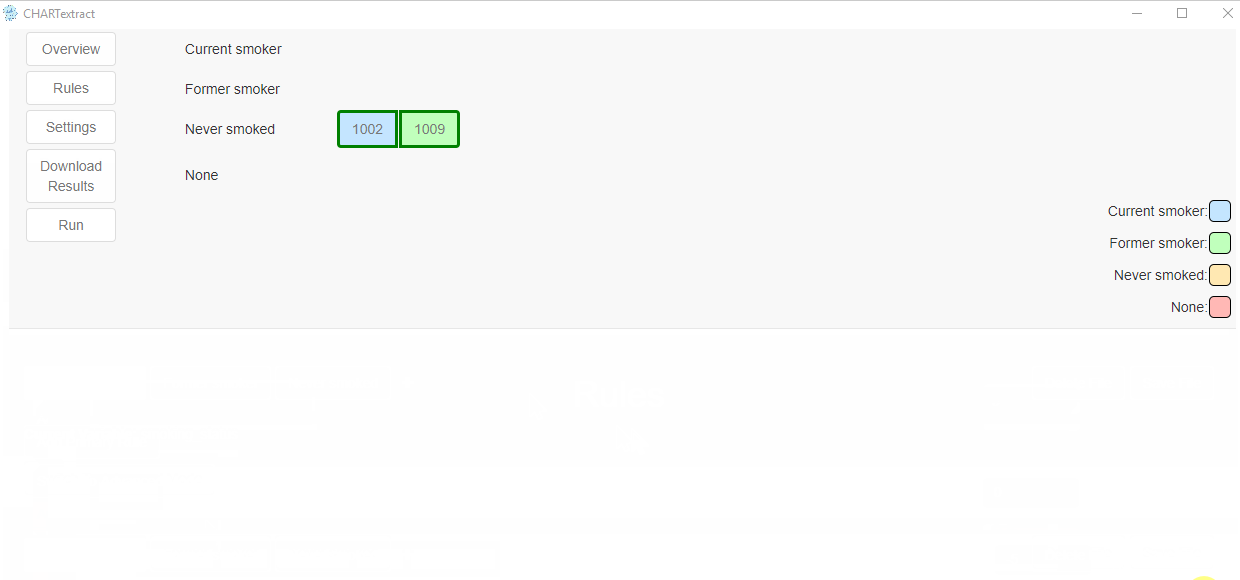
- Go back to the rules view. Press on the
Current smokerlabel. - Add a secondary Ignore rule to the second Primary rule (Rule #2). In the text input field, add the following:
former. Press on the dropdown menu next toappears, then score, and selectAppears Before 2. This rule will be ignored if the wordformerappears before it. - Re-run the tool by pressing on the Run button.
- You’ll notice that now chart with ID 1003 no longer shows up in the misclassified instances.
Further exercises:
- Write your own rules.
- Try this in the advanced view.